[Swift] Encrypted fraud detection
The Challenge: Screening Without Decrypting
Swift transactions are encrypted in transit. That is by design. But fraud screening and sanctions checks need to happen in real time, as payments flow. Today, that means decrypting the transaction to run the check, then re-encrypting it. The data is exposed, even if only briefly, and the pipeline has to be trusted end to end.
The goal Swift set with us was simple to state and hard to achieve: screen encrypted transactions against sanctions lists in real time, without ever decrypting them. Fully Homomorphic Encryption makes this mathematically possible. The problem has always been that FHE is far too slow to meet real-time requirements. A check that takes 4 minutes per transaction is not fraud detection, it is a batch audit.
At Belfort, we are changing that. In this post, we explain how we brought encrypted fuzzy name matching’s latency down from 4 minutes to below 1 second and what that means for real-time fraud screening at scale.
Why Fuzzy Matching?
Sanctions screening and fraud detection depend on matching names in transaction data against watchlists. This is harder than it sounds: names are misspelled, transliterated differently across languages, or contain minor variations. "D'Anvers" and "DAnvers" typically refer to the same person but a strict character-by-character comparison will fail.
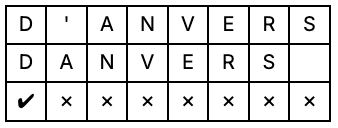
More specifically, we need to compute the edit distance or Levenshtein distance, which counts the minimum number of insertions, deletions, or substitutions needed to transform one string into another.
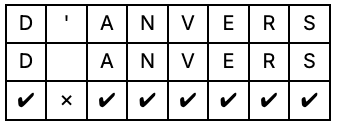
The catch is that Levenshtein distance is computationally expensive. The cost scales quadratically with the string length. Under FHE, where every operation carries significant overhead, this was completely impractical until recently.
Algorithmic Optimisations: 321x Faster in Software
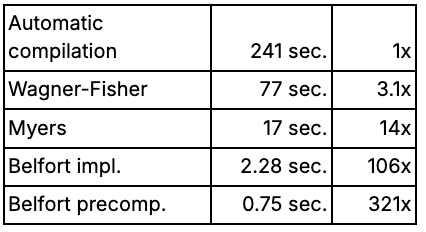
Together with Swift, we defined a concrete target: run Levenshtein-based name matching on fully encrypted bank transactions, without ever decrypting the data. The starting point, an automatically compiled FHE implementation of the standard Wagner-Fisher algorithm, took 241 seconds per transaction. That is a research curiosity, not a product.
The first lever is algorithm choice. Not all algorithms are equal under FHE, and the standard Wagner-Fisher approach turns out to be a poor fit. The Myers algorithm, which uses a boolean representation instead of full integers, maps far more naturally to FHE's native operations. This results in a runtime of17 seconds: 14x faster, no hardware changes.
Three further FHE-specific optimisations — a more compact data representation, computing two results from one expensive operation, and collapsing a multi-step calculation into a single lookup — bring this to 2.28 seconds and a 106x total speedup.
The final software gain came from an unexpected observation: at this point, most of the remaining compute resource was spent comparing character pairs, not computing the edit distance itself. Since the sanctions list is not encrypted, those comparisons can be precomputed once and reused. That single insight delivers another 3x improvement, reaching 0.75 seconds and 321x over the original baseline.
Hardware Acceleration: Closing the Gap to Real Time
The AI boom was fueled by GPUs, and similarly, FHE will benefit from dedicated hardware units. The first such units are only now becoming available, and their speed is expected to increase significantly in the coming years.
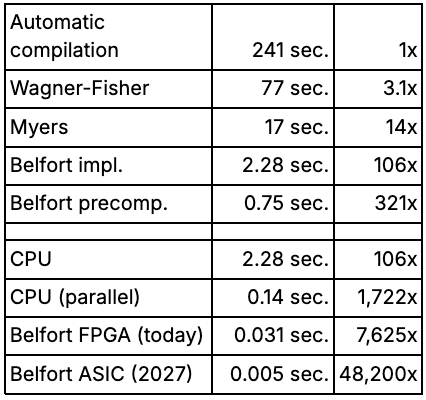
For a fair comparison, it is worth noting that TFHE operations can be parallelised across cores. Exploiting this on a 32-core machine reduces average processing time to 0.14 seconds, a 16.3x speedup over a non-parallelised implementation. For longer strings, speedups of up to 30x were observed, approaching the theoretical maximum of 32x. This is the realistic CPU baseline against which dedicated hardware should be measured.
On that baseline, Belfort's FPGA accelerator makes a dramatic difference. Running on dedicated hardware explicitly designed for TFHE, the same workload completes in 0.031 seconds — a 7,625x speedup over the original baseline, and more than 4x faster than the parallelised CPU. This is the level of performance that makes real-time encrypted screening a realistic proposition.
Our Belfort accelerator integrates seamlessly with the TFHE-rs library. To run your program, you'll need a Belfort-enabled computer (Belfort's latest-gen Velox accelerator is publicly available for early access) and to modify three lines in your TFHE-rs code's preamble. Below is an example of these changes.

What This Means for Financial Institutions
At sub-second latency, encrypted fuzzy matching becomes operationally viable for the first time. Transactions can be screened against sanctions lists without ever being decrypted, eliminating the exposure window that today's systems all share. No need to trust the cloud provider, the hardware, or the administrator. Trust the mathematics.
This matters beyond Swift. Any institution that needs to screen sensitive data against a reference list, whether correspondent banks, payment processors, or compliance teams operating across jurisdictions, faces the same tradeoff. Belfort's approach resolves it.
"Fraud screening and data privacy have always been in tension at Swift. To check a transaction against a sanctions list, you need to read it, which means exposing it. Working with Belfort, we saw for the first time a credible path to resolving that tradeoff: running fuzzy matching directly on encrypted transactions, without ever decrypting them. That changes the conversation."
- Nam-Luc Tran, Product Owner Anomaly Detection, Swift
What's Next
Now is the right time to start building with FHE. The performance barriers that made it impractical are coming down faster than most people expect. Our FPGA accelerator is available today on Amazon AWS. The ASIC roadmap targets 5ms latency by 2029, opening the door to real-time encrypted screening at full transaction throughput.
If you are working on sensitive data workflows in financial services, compliance, or fraud detection, we would like to hear from you.
Further Reading
This work builds on research from KU Leuven’s COSIC research group on efficient encrypted string matching. In particular, see “Leuvenshtein: Efficient FHE-based Edit Distance Computation with Single Bootstrap per Cell” presented at the USENIX Security Symposium 2025, which introduces a new algorithm for computing Levenshtein distance under Fully Homomorphic Encryption with far fewer bootstrapping operations.
Link: https://www.usenix.org/conference/usenixsecurity25/presentation/legiest
About Belfort
At Belfort, we believe that in an AI-first world, trust is all you need and the future of computing is encrypted. Belfort enables that vision by accelerating encrypted compute to make it practical at scale, ensuring that sensitive data can be processed without ever being decrypted. A spin-off from KU Leuven’s world-renowned COSIC lab, Belfort combines breakthroughs in hardware and algorithms to build the next layer of secure computing. The company has offices in San Francisco, USA, and Leuven, Belgium. https://belfortlabs.com.

